


Table Of Contents
510 pages, published in 2004. The book is quite old for a tech-book but it has aged exceptionally well. It only shows age in a few unimportant areas in my opinion.
The concepts presented in the book have revolutionized me as a developer! Read it multiple times and with great attention to internalize all the knowledge it contains, it will be worth it. To really understand the concepts and integrate them you should also build a project as you read the book where you implement the examples.
I cannot recommend this book enough! Below is my notes from reading the book, it is partly a summary of each chapter and partly my own thoughts about the content.
Chapter 1-3
Ubiquitous language is the most important concept when running a project as domain driven. It is essential to facilitate that developers talk to the domain experts. A way to do this is to build prototypes for the domain experts to evaluate.
The core learning is to create a forum where the developers and domain experts can learn from each other while collaborating to creating the ubiquitous language.
Developers are good at creating software, but the software can only be as good as the understanding of the problem area. If the domain is complex, in most cases, the domain experts have implicit knowledge that they can not easily communicate, but by creating simple prototypes and discussing the domain model, it should be possible to bridge this gap.
It is essential to keep the ubiquitous language in sync with the domain model. If one change, the other should also change. A simple example of this: if we agree on a name of a concept we naturally start using this name in the code for class names and variables. If we later find a name that describes the concept better the code must change to reflect this. If we do not change the code, any developer looking at it later might not connect the erroneous name with the domain concept.
We can not ask the domain experts to tell us what they want the software to do. It will often lead to either too detailed technical descriptions or to abstract concepts.
Starting up the discussions can be difficult because progress in the start will be slow until the participants get tuned in to each other.
The initial domain model, which might take several meetings to flesh out should result in a prototype. We prototype because it allows us to see if we as developers understand the domain correctly. If we are able to connect the details in the domain in a program that outputs something useful. This process is iterative.
Chapter 4, Isolating the Domain
A system consists of many responsibilities: UI, database, business logic and so on. It is important to isolate the domain-related code from other concerns. If the business logic is diffused throughout the system then it eventually becomes harder and harder to change anything.
One way to do this is to apply layers, this is standard practice, and makes the domain objects clutter free. It is important not to get caught in the trap of depending on a framework unless it is needed. It can become to heavyweight and make the domain difficult to understand.
Not all projects benefit from a domain driven approach. In some cases what you need is a “Smart UI.” If the business rules are all simple and there is no future need for supporting complex business rules, then the overhead of the domain-driven approach might be too high. In this case, you could put all the logic into the UI without much worry. Remember that the approach should fit the task.
Chapter 5, A Model Expressed In Software
A domain model consists of the basic elements ENTITIES, VALUE OBJECTS, SERVICES, and their associations.
In real life, there are lots of many-to-many relations. However, they are not always helpful or easy to work with inside software. Often there are ways to communicate the intent of the association better by adding constraints.
For example, the relationship between country and president, is bidirectional one-to-many. But one of the directions is more significant because we most often start with the country, and not with the president.
We can qualify this even more by adding a constraint like period on the association so we can ask, “who was the president of the USA in 1998”.
We can make associations easier to work with by adding different constraints like: Imposing a traversal direction, adding a qualifier to reduce multiplicity or eliminate associations that is not strictly needed.
Entities: An entity is defined not by its attributes but by a thread of continuity and identity. Even if you have the same name and age as another person you still have unique identities.
An identity is the same across multiple systems, for example with medical records, when changing hospital you still need to be identifiable using some unique identity. Even if the same identifier is not used across systems, the entity is still the same. For example, a transaction using cash is still the same transaction when you hand the cashier the money and when it is debited to the store’s account.
Value Objects: These objects describe some characteristica of a thing. A value object is much simpler than an entity. If only the attributes of an element are important and no continuity is needed, it is a value object.
In some cases, a concept is an entity, and in others, it is a value object. It depends on context. For example, an address, if you order something to be delivered, it would not matter if your roommate also ordered something at the same time. The delivery service could treat the address as a value object.
But if you ordered electrical service, then the service company needs to be aware if your roommate also ordered to the same address. In this case, the address is an entity.
Services: Sometimes, it just isn’t a thing. Some important operations are not natural to place in either entities or value objects. They are activities but we must fit them into objects anyway.
If we fit the action into a wrong object the object loses clarity and becomes hard to understand. Often actions also depend on many different objects so the dependency graph becomes difficult to understand.
A service should be added as a standalone interface declared as a service. Also, make the service stateless. The stateless behavior makes the service not depend on any state which makes it behavior simpler.
Services exist in different layers, not only in the domain layer. There are also services that exist in the infrastructure and application layer. The distinction is not always clear, and it takes care to factor the responsibilities correctly.
If we take the example from the chapter: A bank has an application that sends an email to a customer if the account balance falls below a threshold.
Infrastructure layer services: This type is the easies to explain. They are purely technical like email or sms services. They are used by the domain and application services to implement the actual sending of messages.
Application layer services: It is the reponsibility of the application service to order the notification. The domain layer is responsible for knowing when the treshold was met.
To quote the book: Many domain or application services are built on top of the populations of entities and values, behaving like scripts that organize the potential of the domain to actually get something done.
Chapter 6, The Life Cycle of a Domain Object
All objects in a system have a life cycle, they are created, changes states and gets removed. Some objects are simple, others are complex. We need to take special care of the complex object. The challenges are:
- Maintain integrity throughout the life cycle
- Prevent the model from getting swamped by the complexity of managing the life cycle
It will be managed by applying three patterns, aggregates, factories and repositories.
Aggregates: Most business models contain many complex relations between objects. It creates fuzzy boundaries where we can end up with a huge interconnected object hierarchy. It can lead to problems with maintaining consistency. To avoid this, we must promote some of the objects to aggregates for a group of objects. Only inside the aggregate, we need to maintain consistency.
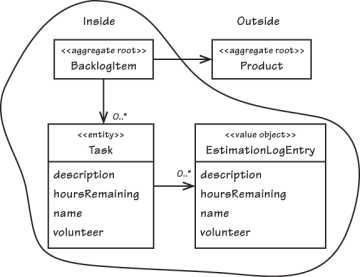
Outside the aggregate, every reference only points to the aggregate root. And all access to the other objects is accessed through the aggregate root.
Those rules make it possible to maintain consistency inside the aggregate because access is controlled. More thoughts on aggregates.
Factories: Creating an object can be complex. We do not want to have this complexity encapsulated inside the constructor of an object. The example in the book is: we need a car factory to build a car. A car does not need to know how to build itself.
The construction logic is separated out, into a separate factory. Additionally, we want to create a factory interface that the domain depends on, the concrete implementation is abstracted away.
A factory is a good choice to create an aggregate. But what if we need to create an object of a class inside an aggregate?
One option is to add a factory method on the aggregate root, for example, if the aggregate root is a Purchase Order, it could have the method newItem() to create a Purchase Item object and add it to the aggregate. This will work fine if the new object is part of the aggregate.
If the object is not part of the aggregate it needs to be an aggregate root which should have a factory for constructing.
When designing an interface for a factory keep this in mind:
- Each operation must be atomic
- The factory will be coupled with its arguments
Repositories: To do anything with an object, a reference to it is needed. This reference is obtained by traversing an association in the domain model. However, we do not always want to add associations since it muddles the model. A better way is to use a repository to recreate a domain object from persistence.
To access aggregates we often need to search them based on object attributes. From the aggregates, we can traverse the associations to get to other objects. We do not want to allow free database queries since that can break the constraints imposed by the domain model.
A repository implements an illusion of an in-memory collection of all objects of that type. Only provide repositories for the aggregates that need direct client access, to keep the clarity of the model.
If complex access is needed to search for objects, a specification pattern can be implemented in the domain language.
Chapter 7, Using the Language: An Extended Example:
In this chapter an example of a system is discussed. The system implements a small domain model for handling shipments of cargo.
The first point is; to use a system, many user-level application functions must be defined. One of the functions is a tracking query to allow us to see the handling events of a particular cargo. The application classes are coordinators. They must not work out the answers to the questions they ask. That is the responsibility of the domain layer.
It is not always necessary to have a repository for an aggregate root. If there is no application requirement for looking up an aggregate and it is only referenced from other entities, then the repository is not needed.
When our domain grows we must take care to group the domain objects into modules. Do not fall into the trap of grouping all entities into a module and all values objects into another module. Instead, the modules should reflect meaning like “Customer”, “Shipping” and so on. Each module should contain the entities and values that have a relation to each other.
In the example an external system needs to be integrated into the existing application. To make sure the external system do not corrupt the existing model an anti-corruption layer is added so shield the model.
In the example the external system holds information about how much may be booked of a particular cargo type. To handle the translation between our system and the external system an “Allocation Checker” service is added. This service acts as the anti-corruption layer.
Chapter 8, Breakthrough
When the model is continiously refined we will only see small improvements until we reach a ureka moment where a refinement makes the model much more expressive and sends a chock through the project.
It is the small increments of improvement that paves the way for the big improvements. The model becomes a deep model that expresses a deep understanding of the domain. It should allow the communication between the technical and business staff to improve because the model gives a shared language that improves understanding across the project.
The chapter goes through a story about how a breakthrough happened in one of the projects the author worked on. A new understanding of the domain often requires a large and scary refactoring to make the required changes. It requires courage to do the needed changes.
In many cases a breakthrough will clarify the model to allow other problems to be visible. This causes a cascade of improvements that makes the model much deeper.
Chapter 9, Making Implicit Concepts Explicit
How do we make a deep model? The power in the deep model is that it allows us to express the knowledge, activities, problems, and solutions in the domain. Flexibly and succinctly.
In the beginning, the developers are novices in the domain so how do we extract the deep model from the business people? It is going to happen gradually, and the chapter presents ways to extract knowledge.
First the concepts must be found. It can happen in different ways, by listening to the language of the team. If the domain experts use terms that express a concept in the domain, but it is not part of the domain model, then it is a hint that the concept needs to be added to the model.
Listen to conversations: In other cases the missing concepts are not part of the conversations. Then you must dig and invent in the most awkward place in the model. In the place where every new requirement adds complexity. With help from the business partner, this area can be understood better, and the model improved.
Contradictions: In some cases domain experts see things in different ways. Sometimes even contradictionary. This often indicate an area where a deeper model can be achived.
Read the book: If there is already litterature on the subject discussing terminology and fundamental wisdom, you may be able to start with a deeply considered view.
Explicit constraints: When doing object-oriented modeling, constraints on objects often come up. For example, a class implementing a bucket which has a limited capacity is a constraint. The constraints are often implicit but making them explicit can improve the model. The constraint can either be factored into a separate method in the class or into its own class entirely.
Processes as Domain Objects: Procedures should not be a prominent part of the model. But some processes encapsulate business meaning and can be implemented as a service. The way to decide is if the process is something domain experts talk about or not.
Chapter 10, Supple Design
Software must serve users, but first, it must serve developers. Developers refactor, extend and build on the software. As times go on and the software is in maintenance mode developers will still change the code.
If the software lacks good design it is increasingly difficult to change. As soon as developers are not confident in the changes they make, duplications appear. Developers will be unhappy working in the codebase. This effect is often seen in projects where over time the amount of effort to make new features or fix bugs increase until the projects reach a standstill.
The way to make sure software is changeable is to make the design supple, and it complements deep modeling. Making a design supple is an iterative process where refactorings are tried out, implicit concepts are made explicit. In this chapter the author covers which experiments to do and how to gain a better understanding of the architecture, we want to code towards.
A developer has two roles when programming, in one role he is a client that uses the domain objects in the application code. The domain should make it easy to express the scenarios needed in the application, and the elements should fit together naturally. In the other role, the developer works to change the domain. It requires the design to be open to change, and consequences of a change must be easy to understand.
The rest of the chapter goes through a series of patterns to use to arrive at a supple design.
Intention-Revealing interfaces: it must never be a requirement for a developer to know the implementation of a component to use it. It that level of knowledge is needed we lose the value of encapsulation. It goes a long way to name classes and operations in a way that describe their effect and purpose. It helps to use Test Driven Development to make sure the intent of the code is clear.
The example from the chapter is a simple Paint class. The class has a method named “paint” but that does not reveal what the method do. Instead it should be renamed to “mixIn” to show that the method mixes paints together.
Side-Effect-Free functions: Operations can be divided into two types, commands and queries. Commands modify the state of the system and queries only reads information.
A side effect happens when a method is called and some state changes. As we combine multiple methods calls in arbitrary depths, it gets tough to reason about which side effects are triggered. It limits the level of richness the developer can express.
A function is a method that we know does not produce a side effect. In any system there should be as many functions as possible. Strictly segregate commands into very simple operations that do not return domain information.
The example in the chapter deals with two objects each representing a volume and color of paint. If we use the mixIn method from above what will happen with the two objects? Should the state of paint 1 change to the new combined color and volume of the two paints? What about the volume of paint 2, should it become 0 after the mix?
To avoid this problem the paint objects can be immutable value objects such that a mixIn returns a third paint object causing the two other paints to have no change. It is a case that is much easier to reason about.
Assertions: There will still be a collection of methods on the entities that produce side effects. Assertions make side effects explicit and easier to deal with.
When calling a method that delegates the work to other methods the only way to know which side effects is being triggered is to trace the branches through the program. It breaks encapsulation. It also depends on the implementations because interfaces do not enforce anything about side effects breaking abstractions.
The concept is taken into the programming languages in the “design by contract” school. In C# there exist Spec Sharp but there is not standard language support for the concept.
The example from the chapter refactors the paint concept further to only have a single method with a side effect. They defer the responsibility for the assertions to the test code. In my opinion, this forces a developer using the component to read the tests to get the correct understanding of the component. It is a bit unelegant I think. However, to make it better language support is needed.
Conceptual Contours: This pattern deals with effective decomposition. There are two extremes when dealing with decomposition. In one case the concepts are grouped in a large monolith. This forces duplication because it is impossible to reuse parts of the monolith and it is difficult to understand. In the other case, if the decomposition is too fine-grained, it forces the client to understand how the tiny pieces fit together.
We should try to find the deep consistency in the domain and group design elements into cohesive units. This grouping is based on intuition about the domain. The resulting interfaces should logically make sense in the ubiquitous language.
The contours often only show up after a lot of refactoring towards deeper insights.
Standalone Classes: All dependencies in a class makes it more difficult to reason about. The more dependencies there are, the more difficult testing will be. The difficulty will increase exponentionally.
Low coupling is the fundamental design to strive for. If all dependencies are removed the class can be understod by it self. This eases the cognitive load when understanding a module.
Closure of Operation: In the pattern above we risk dumbing down our model because we remove dependencies to a point where it gets less expressive. This pattern deals with how we manage the dependencies.
When it fits we should define return types as the same type as the arguments. I think this is what is also known as a fluent interface.
It can benefit us to create a more declarative style of design. As with everything, this can be taken to extremes like model-driven design, where code generation tools generate the actual code. That approach is not always flexible enough. The chapter elaborates on how to change the specification pattern to be more supple and declarative. It shows how to extend the specification to use and/or/not operators to combine specifications.
Chapter 11, Applying Analysis Patterns
As a software developer, you know about design patterns. Their purpose is to solve a low-level technical problem in a proven way.
Analysis patterns are in a way the same except that it focuses on the domain instead. It makes the patterns both more domain-specific, but at the same time, it allows us to capture more high-level concepts. If there already exists an analysis pattern for what we are trying to achieve it can help produce a good solution faster because we can avoid some of the refactoring steps.
The only resource the chapter points to are Analysis Patterns by Martin Fowler, but it is quite an older book. There does not seem to be written that much on this topic as far as I have been able to find.
Chapter 12, Relating Design Patterns to the Model
Design patterns are well known in the software development literature. However, the focus in design patterns is mostly technical. However, some of the patterns can be used in a domain model as well. Our thinking needs to be a bit different. The author shows two examples using the Strategy Pattern and the Composite Pattern.
Strategy (policy): A domain model contains processes that are meaningful for the domain and not technically motivated. In many business domains, there is a need to have different processes to solve to the same problem. Even though the strategy pattern is technically motivated, it fits exactly this purpose, to separate the different part of a process into different policies.
The chapter example is about finding routes for package delivery. We could have the policy to save money for each leg of the journey or look for the fastest route. In this case, the strategy is not just implemented for a technical reason but just as much for domain value.
Composite: In many domain models we end up modeling concepts that consist of parts that we can arrange arbitrarily, into a tree structure. If we do not see this and start implementing each part as a unique concept instead of seeing it as being composable. Then we will end up with duplication, and it will prohibit the flexibility of the model.
The example in the chapter is routes made of routes. A route is a complex concept that consists of routes with legs. Since each “sub-route” can be planned and managed by different persons, it needs to be a concept on its own. It is where the composite shines.
Chapter 13, Refactoring Toward Deeper Insight
There are three major points to consider to gain deep insight
- Live in the domain
- Keep looking at things in a different way
- Maintain an unbroken dialog with domain experts
In this chapter the author walksthrough different aspects on how to improve the domain model.
Initiation: The first step to getting a better model is to see the problem. It might show up in awkward parts of the code because of a missing concept. It might be that the language in the model is disconnected from the language the domain experts use. However, when the problem is located the model can be refactored.
Exploration Teams: If we already have an idea for a refinement of the model we can refactor the code directly. But in some cases the search for a new model is more involved and require more time and involvement from the team.
A team of a few developers and a domain expert get together to sketch a new model, in a conference room for a ½ hour to 1½ hour. It should result in a rough idea for a model. The team might need to sleep on it and get together again to reach useful conclusions. The key points to get it to work are:
- Self-determination, a small team can be assembled on the fly to explore design problems. There should only be a need for a shortlived team.
- Scope and sleep, Two or three short meetings spread out across a few days should give a model that is worth trying out.
- Exercising the ubiquitous language, use the language and refine its use in brainstorm sessions with the rest of the team and a domain expert.
Prior Art: Use knowledge from books about the domain. If there are analysis patterns, use them. Design patterns can often also be used to model concepts in the domain.
A Design for Developers: We develop software for users, but it must also be developed for the developers. The code is going to change again and again when it is refactored towards deeper insights. When a design is supple, it is easy to see the intent and easy to anticipate what will happen if it is changed. That is what makes the design work for the developers.
Timing: If you wait until you can make a complete justification for a change, you have waited too long. The more changes are postponed, the more costly they are to change and harder. Most teams are too cautious about refactoring. It is “easy” to see that refactoring is going to be expensive to implement. However, the cost of working around a bad design is often higher than the refactoring cost. It is just more difficult to see.
Refactor when:
- The design is mismatched with the team’s understanding of the domain
- Important concepts are implicit in the design
- There is an oppertunity to make important parts more supple
Crisis as Oppertunity: Notice that when reading about refactoring it seems like a slow and incremental process. Often it is not like this, refactorings lay a groundwork for sudden insight that reveils something in the domain that reads to a sprout of refactorings towards deep insight.
Chapter 14, Maintaining Model Integrity
This chapter and the remainder of the book goes into strategic design, so it is more high level. I think the advice is more suited for larger projects with more people. However, many of the points make good sense to implement when starting a new project.
A model must be logically consistent to make sense. When having a system that must span a large domain, it would be ideal to have a single model. However, that becomes difficult/impossible to do as the model grows. The example from the chapter is two teams working on the same system. One team have implemented an object named Charge. When the other team started implementing a billing module, they needed a Charge object as well and to reuse code, and they reused the implementation already in the model. However, their changes created bugs in the original implementation.
They ended up splitting into two models. It is often to costly or not feasible to create a unified model. Some of the risks are
- Too many legacy replacements may be attempted at once
- Large projects may bog down because the coordination overhead exceds their abilities
- Application with specialized requirements may have to use models that don’t fully satisfy their needs, forcing them to put behavior elsewhere.
- Conversely, attempting to satisfy everyone with a single model may lead to complex options that make the model difficult to use.
The remainder of the chapter provides patterns for how we can create boundaries and communicate relationships between different models. The list of patterns is a bit long.
Bounded context: When building a large software system, even on a single team, different models emerge if we are not careful. It is easy to see when integrating with an external system that the two systems have different conceptual models. However, different models might also arise in the same codebase. It could be that some parts of the code reflect an older understanding of the code. When combining the models’ errors happen, making the system less reliable and more difficult to understand.
A model applies in a context, so we should start by explicitly defining the context the model applies. Teams working in the same context needs to communicate a lot to create a shared understanding. If the teams only communicate once in a while, they are not working in the same context, and the model will fragment.
When a bounded context is defined it creates two advantages, the team(s) working inside the context knows that they must keep the model consistent. Also, any team working outside will use a translation layer to communicate with the model, giving them much more freedom.
When fractures in the model happen the remainder of the patterns give advice on what to do.
Continuous Integration: In a bounded context it is not always possible to break it down into smaller contexts because it loses valuable information and options. Multiple problems can challenge the model. If a developer is not aware of a concept in the model and builds a similar concept, we end up with duplication and the problem with two concepts that diverge. A similar problem happens if a developer is overcautious and knows the concept in the model but because of the risk of change duplicates instead.
Advice for having better control and more confidence in the code are
- Reproducible builds
- Automated tests
- Rules for integration of code changes
- Use the ubiquitous language in the team to facilitate communication
Continuous integration is only used inside a bounded context, there is not need for it across multiple contexts.
Context Map: With multiple bounded contexts the need to interconnect them will occour. When that happens it is important to have a model for that to avoid the teams to start blending the boundaries between the contexts. A context map is overlapping project management and software design.
Team members that sit together will naturally start sharing a bounded context. However, be aware of team members that sit in other locations, it will require extra integration efforts to share the same context. In many cases, a small diagram with the names of the different bounded contexts is enough to make the distinction visible to the developers.
Contact points between bounded contexts are important to test because tests can alert about errors before they become a problem.
Shared kernel: In some cases there is significant value in reusing the same parts of the model across multiple bounded contexts. However, continuous integration is too expensive, in this case, a shared kernel can be defined, containing a subset of the domain model. The subset is shared, and coordination must happen for any change in this part of the code.
Customer/Supplier Development teams: In many systems there are subsystems which receives data from our system. The subsystem might also be built using another language making code sharing impossible and it might also server another user group. Naturally, the systems are in different bounded contexts. There is a delicate balance between the systems. If the subsystem developers do not want to implement the changes we request, our system might be impossible to develop. In the same way, if we have veto power to stop changes in the subsystem, it will make the subsystem difficult to develop.
The differences can be accommodated by making all teams part of planning to make sure priorities are aligned. Developing automated acceptance tests also goes a long way to make sure the interactions between the systems keep working.
It is crusial to make sure that the teams can coorporate, if not the relationshop can break down.
Confirmist: If the customer/supplier relationship can not be established the team might need to shift to be a conformist. We have two options if integration to the other system is needed. Either set up an anticorruption layer that can absorb any changed the other team makes. Alternatively, if the models are largely compatible, it can be used directly, and our system conforms to the model of the other system.
Anticorruption Layer: When we are tasked to integrate with a legacy system or other external system the often have their own model. It is important that our domain model is as expressive as possible, so we do not want the model of the external systems to leak through and “pollute” our domain model.
To make sure leaks do not happen an isolation layer is created. The purpose of the layer is to contain any translations needed to communicate with the external systems and do any semantic translations to our domain model. If the layer is strict, it should allow us to develop our domain model without worrying about the semantics and model of external systems.
The public interface of the anticorruption layer usually is a list of services with the occasional entity. Such a new layer allows us to re-abstract the behavior and model of the other system in a consistent model. The layer itself is often built from some facades, adaptors, and translators.
Separate Ways: Integrating systems are expensive. Integrations are not always needed. If we can manage with a hyperlink in a UI to an external system, that is a much cheaper solution.
Open Host Service: Each bounded context need a translation layer for each component it needs to communicate with outside the context. But if the component needs to be used by many others it might be cumbersome to create customer translators.
In this case it might make sense to create a protocol that exposes a list of services. Like a REST api service or similar.
Published Language: Translating between two bounded contexts require a common language. This language can become complex and hard to document. If businesses need to exchange data they probably do not want to conform to the language of the other party.
In some domains a language is developed to support a common language. Examples of it is BIAN, CML, and many XML schemas. If a language already exist it is worth researching if it can be used.
The rest of the chapter is dedicated to points on how to move the project between the different patterns, from Separate ways to shared kernel to continuous integration and so on.
Chapter 15, Distillation
If the domain gets large it become difficult to manage. By distilling the domain, core concepts can be communicated more clearly. As we refactor towards deeper insight the model gets more clear, but how do we manage it when the domain is large. We want all team members to see the overall design and how it fits together. The model should facilitate communication by having a core model of a manageable size to allow new team members to use the ubiquitous language. Distillation should guide refactoring and focus work on areas of the model that gives the most value.
The chapter contains a list of patterns to help us reach those goals.
Core domain: In a large system there are going to be many contributing components. However, many components will obscure the essence of the domain model. If the system is hard to understand it is hard to change. Not all parts of the design are refined equally. The critical core should be sleek and fully leveraged to create functionality.
The core should be easily distinguishable from the rest of the domain model. Also, it should be small. Make the best developers work on the core to make it pristine. It must be refactored to be a deep model and be supple at the same time. We should focus on investments in other parts of the system based on how the other parts support the distilled core.
The remaining patterns help us make the core easier to see, use and change.
Selecting which part of the domain model to include in the core is not an easy task. Even if a concept is central to the model, like generic money, it might not be important enough to include in the core unless it is a money trading application we are building.
Generic subdomains: Some parts of the model might not capture or communicate any specialized knowledge. Those parts should not be part of the core domain, general concepts that all knows and plays a supporting role will pollute the core model.
Identify cohesive subdomain that is not the primary motivation of the software. Separate them into separate modules that do not reference any of the specialties. After that, they can be developed independently of the core domain and with a lower priority. This separation also allows us to consider different options for developing the subdomain.
- Off-the-shelf-component
- Published design or model
- Outsourced implementation
- In-house implementation
Each option have different advantages and disadvantages explained in the chapter.
Domain vision statement: When the project is started there is no model but we still need a way to focus effort. Later in the project we need to communicate the value of the system without an in-depth study.
To facilitate those needs a vision statement can be created, this is a description about one page long describing the core domain and its value proposition. It should be written at the beginning of the project and revised as new insights are found.
Highlighted core: The vision statement creates an overview of the core domain. But it is still up to individual interpertation. If the team does not have exceptional communication skills it will not have much impact.
To highlight the core structural changes needs to be made in the code. However, that is not always practical to do, and it often requires the overview that is lacking. So a lighter approach is to highlight the core. One way is to create a distillation document that contains a list of essential objects and maybe a few diagrams. It is not supposed to be a complete design document. Max three to seven pages.
Another way to highlight the core is to create a flagged core. In the documents that show the design the essential elements are flagged, this can be as primitive as post-it notes in a printed design document. It allows developers to navigate the core more easily.
Cohesive mechanisms: In OOP we want to separate the “how” from the “what” in our algorithms to hide complexity. However, we sometimes hit limits in this approach. When our code starts to be bloated and difficult to read because we have too much “how” in the code, we need a different approach.
Create a lightweight framework which uses intention revealing interfaces to hide the “how”, now the domain code can be made more clear.
Segregated Core: When there are elements in the model that serve both the core domain and supporting roles the core might be coupled to generic concepts. This causes clutter that makes the model less clear.
The code should be refactored to separate the core concepts from the supporting concepts. This should strengthen cohesion in the code while reducing coupling to other code.
The steps are usually:
- Identify the core domain
- Move related classes to a new module, named for the concepts that relate them
- Refactor code to remove the connections to data and concepts that are not directly related. Scrub the core domain to make it self explanatory
- Refactor the newly segregated core module to make it simpler and more communicative.
- Repeat with another core subdomain until the segregated core is complete
Chapter 16, Large-Scale Structure
When systems grow very large, even breaking ít up into modules may not be enough. In some cases, the system grows to be too complex and contain so many modules that the amount of modules alone causes problems of understanding the system. In this case, the developers are not able to see the forest for the trees.
A patten of rules or roles and relationships that span the entire system must be created. It should allow understanding each part’s place in the whole, without detailed knowledge of the parts them selves.
Evolving order: If there are no constraints on the design of a system it will evolve into a system that nobody understands and is difficult to maintain. However, if we impose strict design constraints and up-front assumptions, it can hinder the development of the system because it limits modeling power. It causes the developers to dumb down the system to fit the structure, or not have a structure at all.
A large scale structure should be applied when we find a structure that greatly clarifies the model in the system. An ill-fitting structure is worse than no structure at all, so aim for a minimal solution.
Responsibility layers: In a large structure, if each individual object has handcrafted responsibilities there are not enough structure and guidelines that make it possible to handle whole parts of the domain together. Impose some structure on the responsibilities to make it easier to handle.
We should refactor the model, so each domain object, aggregate, and module fit into the responsibility of one layer. Layers should communicate the realities or priorities of the domain. It is primarily a business modeling decision how to structure the layers.
“Upper” layers should make sense on the backdrop of the lower levels, and the “lower” levels should stand alone.
Different examples of layers that fit many different types of domains are suggested in the chapter. The layers are business oriented, so according to the author the layers presented will fit almost all domains.
Knowledge level: The more generic a domain needs to be, for example if we need objects to interact based on rules that are changeable by users, the more complex the system gets.
It could be a CRM system where each installation is customed for specific customer needs by configuration. In this case, we need a distinct set of object that describes and constrain the structure and behavior of the basic model. A “meta-level” of sorts.
Pluggable component framework: With very mature models that is deep and distilled, opportunities arise. With multiple systems that need to interoperate, but are based on the same abstractions and designed independently. We need many translations between the systems, and a shared kernel is not feasible because the teams do not work closely together.
In this case we could distill an abstract core that contain interfaces and create a framework that allows multiple implementations that can be substituted easily.
The example in the chapter is Sematech CIM framework, which is a framework for industrial machines for semiconductor manufacturing. The software of each machine must adhere to the interfaces designed in the CIM framework, but when it does that, it is freely interchangeable.
Chapter 17, Bringing the Strategy Together
The three driving principles, context, distillation, and large scale structure are complementary principles. I see many good points in this chapter but since I am not working on any projects that are that large I have not invested much time in the chapter.
Conclusion
It is a great book, worth reading multiple times to internalize all the knowledge. Huge recommendation from me.
Share

Legal Stuff