


This book is a must read for any serious software developer. It gives a high-level overview of software development that is missing from other more code-oriented books. The primary focus is on Object-Oriented Programming and how we build systems that are maintainable, flexible, extendable and correct. But the approach is high-level so not many code examples.
At 321 pages and 34 chapters, it is not the most extensive book, and it is an easy read because so much of the advice makes perfect sense. But it still has so much depth that I think it can be read multiple times to get all the nuggets of wisdom.
A different view on the book is from Blaine Osepchuk. The only criticism I have of the book is that some of the chapters feel more like intros and does not cover the theme adequately.
I have collected my notes from the book here for all to benefit. But the notes do not give the book the needed credit so please take the time to read it.
Chapter 1 (What is Design And Architecture) It is possible to build software while ignoring all best practice. But over time it will slow down the development. An often used way to combat that is to hire more developers. But it just increases the problem. When the architecture gets messy it takes more time to reason about it. And the risk of errors increases.
The only way to go fast, is to go well.
As software developers, we need to take quality very seriously. Because ignoring it will eventually cripple the systems we build.
Chapter 2 (A Tale Of Two Values) All software consist of two values, behavior and structure. Behavior is what the computer does to save the stakeholder money or make something more effective. The structure is how the software is structured which allows it to change easily.
Often the focus is on behavior to the peril of structure. But this is dangerous to the health of the software system. As Robert puts it:
- If you give me a program that works perfectly but is impossible to change it won’t work when the requirements change, and I won’t be able to make it work. Therefore the program will become useless.
- If you give me a program that does not work but is easy to change, then I can make it work, and keep it working as requirements change. Therefore the program will remain continually useful.
Both values need to be balanced, and it is the professional responsibility of developers to make sure that one is not sacrificed on behalf of the other.
Chapter 3 (Paradigm Overview) Structured, object-oriented and functional programming paradigms remove capabilities from the developer, in very deliberate ways. We should remember that there has not been created a new programming paradigm since 1968 so it is not likely that any other will be invented.
Chapter 4,5,6 (Structured, Object Oriented, Functional languages) In those chapters we dive further into how each paradigm restricts the user and which effect this has.
The rules of software are the same today as they where in 1946, when Alan Turing wrote the very first code.
Each paradigm has different ways of imposing control on the developer. But in the end, they are very similar.
Chapter 7, 8, 9, 10, 11, (The SOLID principles) This is one of the most important parts to understand, and it will guide every line of code you write.
_S_ingle Responsibility Principle: A module should be responsible to one, and only one, actor.
We want a piece of code to be responsible to one actor. Think for example of a class that calculates pay and reports hours. The pay part is used by the financial department, while the reported hours are used by human resources.
If we assume that the pay is dependant on the hours we could have a method shared between pay and reporting hours, that calculates the number of hours.
When the finance department wants a tweak to how hours are calculated, then we change the shared method. But this forces the change on human resources which not want or need the tweak.
Another danger is if the two departments both want changes to the same method, then it is not unlikely that two different teams will be tasked with the assignment. It will end up in a merge conflict creating risk for all involved.
There are multiple ways to avoid this problem. But all of them move the code into different classes that only support one single actor.
_O_pen Closed Principle: Software should be open for extension and closed for modification. We should be able to extend software without making massive changes to it. This principle can both be applied to the class and module level and on the architectural level.
When applied to the architectural level this principle makes us arrange the components into a dependency hierarchy that protects high-level components from changes in low-level components. Often through use of interfaces.
_L_iskov substitution principle: The purpose of this principle is to allow us to exchange a component for another implementation and make sure that our software still works as intended. For example swap a file-based persistence system with a database, without changing anything else in the code that uses the persistence system.
This principle is quite easy to break in subtle ways because a client might depend indirectly on the internal state of the component.
For example, let us say we have a component that models a car, it implements this interface.
public interface Car { bool WheelsTurning(); }
On a regular car if the wheels are turning the car is moving, so a client might use the method as a proxy for knowing whether the vehicle is moving.
But if we implement a car with fancy rim spinners, the wheels could be turning while the car is not moving.
Since the component does not know how a client depends on it, it is easy to break this principle without knowing.
_I_nterface Segregation Principle: When a client depends on a class it depends indirectly on all the methods in that class, even though it does not use them. Instead, extract an interface for the class and make the client depend on that instead.
To minimize dependency, we can split an interface into smaller interfaces. This allows a client to control more fine-grained which dependencies it has.
_D_ependency Inversion Principle: This principle is often confused with Dependency Injection, which is not directly related.
We should always strive to depend on abstractions and not implementations. If a client depends directly on a class name, it creates a dependency directly to the client. This locks the implementation. Instead we should depend on an interface so the implementation can be changed later.
Chapter 12 (Components): Historically, creating plugins for systems have been a considerable effort. But now we can easily support new plugins by adding a .dll, .jar file or others directly in a folder for the system to load. A component is the smallest deployable part of an application.
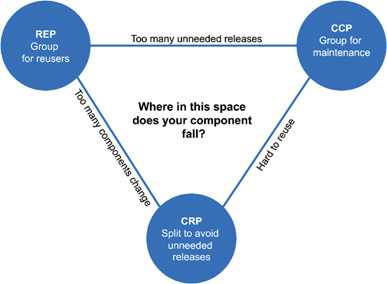
Chapter 13 (Component Cohesion): How do we know which classes belong to which components? Oncle Bob uses three principles
- REP: The Reuse/Release Equivalence Principle
- CCP: The Common Closure Principle
- CRP: The Common Reuse Principle
REP: Each component should be tracked with version numbers because that is the way we track which components are compatible. We decide which classes to include in a component by the rule that it “should make sense” a very weak rule.
CCP: Classes in a component should change for the same reasons and at the same time. A component should only have one reason to change. This principle is very similar to SRP and OCP from SOLID. Just for components.
CRP: When a component uses another component they form a dependency. Even if this dependency only uses a single class inside the dependent component. But the link is still just as strong. This principle is related to the ISP from SOLID.
Don’t depend on thing you don’t need.
The three principles create a tension diagram because they can not all be fulfilled at the same time.
Chapter 14 (Component Coupling):
The Acyclic Dependency Principle, there must never be cycles in the component dependency graph. The book shows its age in this chapter, talking about the problem of weekly builds, where all developers on a team struggle to integrate all the week’s changes to build a release.
I think Git workflows to a large degree solves this. If a project is large, trying to eliminate the dependency cycles is also a good idea. Each team develop their component and release it to shared storage with versioning. Then other teams can reuse the component and only integrate with new versions when they want or need it.
Any cycle in the component dependency graph will give problems because then each team cannot choose when to upgrade every single component, which gives problems.
There are two principles for breaking a cycle.
- Apply the dependency inversion principle by creating an interface that can be depended on and put that inside the child component.
- Create a new proxy dependency that both components depend on.
The component map is essentially a buildability and maintainability map.
The Stable Dependencies Principle, depend in the direction of stability. Any components that are volatile should not be depended on by stable components. Depending on volatile components makes them difficult to change. When using CCP, some components are designed to be volatile, so we expect them to change.
A component with lots of incoming dependencies is very stable because it requires much effort to change it. It leads to a metric for stability with fan-in, fan-out and instability. I have not seen this metric in any code analysis software yet. When drawing a class/component diagram if we place the unstable elements on top, any arrows pointing up is violating the SDP.
The Stable Abstractions Principle, A component should be as abstract as it is stable. Some parts of our software should change infrequent and should be placed into stable components. But how do we make sure that the software is still flexible enough to support the changes we need?
The OCP (Open Closed Principle) answers; this principle tells us that we need to create classes that are flexible for extension but does not require modification, which means abstract classes.
The SAP principle gives us a relationship between stability and abstractness. Combining SAP and SDP gives DIP(Dependency Inversion Principle) for components. It means that dependencies should run in the direction of abstraction.
Measuring this relationship can be done using the Nc/Na/A measurements
- Nc: the number of classes in the component
- Na: the number of abstract classes and interfaces in a component
- A: Abstractness. A = Na - Nc
This relationship is condensed to define the relationship between stability(I) and abstractness (A), giving this diagram.
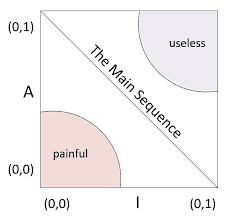
Examples:
- (0,0) Highly stable and concrete, could be a database schema. Very concrete and volatile, hard to change
- (0,0) A concrete utility library. An example could be the base classes in a language like String, Bool and so on.
- (1,1) Usually abstract classes or interfaces that was never implemented.
We want most of our code to be positioned on the main sequence.
Chapter 15 (What is Architecture?): The first quote in this chapter resonated much with me.
First, a software architect is a programmer and continues to be a programmer! Never fall for the lie that suggests that software architects pull back from code to focus on higher-level issues. They do not!
Architecture is the shape of the system, the purpose of this shape is to facilitate the development, deployment, operation, and maintenance of the system.
It should leave as many options open as possible, for as long as possible.
The purpose of the architecture is not to make the system work, many systems “work” fine but has awful architectures. The primary purpose of the architecture is to support the lifecycle of the system making it easy to change.
It can easily happen that architecture impedes in the beginning because the team is small it can easily communicate about changes. But as the team grows into multiple teams, the architecture should be able to divide the system into well-defined components.
Software systems have two types of values: the behavior and the structure. The structure is what makes software “soft,” giving it the most value.
We keep software soft by keeping as many options open as possible for as long as possible. The possibilities that should stay open is the details because they do not matter. Any software system consists of policy and details. The policy is the business rules and is where the value lies. The details are the rest that makes the system able to communicate with the humans and other systems like I/O, databases and such.
Good architecture separates details from policy in such a way that the policy does not know anything about the details.
An excellent example of that is the architecture suggested in the book Domain Driven Design which puts more implementation details on the abstract ideas from this book.
Chapter 16 (Independence): The priority of any architecture is to support the intent of the system, it must support the use-cases. We should strive to allow the architecture to signal at the architecture level which behaviors the architecture supports. A shopping cart application must look like a shopping cart application ( aka screaming architecture ).
Some use-cases require 100.000 customers per second; others require data querying in big datasets in milliseconds. It requires the architecture to be structured to allow this.
It might require many microservices, thousands of threads or a monolithic system. A good architect leaves the options open. If the system depends on the architecture, it will not be easy to upgrade if the requirement switches from, e.g., a monolith to a multiserver system.
It is possible to keep options open by applying some generic rules like, SRP (Single Responsibility Principle)and CCP(Common Closure Principle) to separate things that change for different reasons. It leads to decoupled layers, where the UI layer is separated from the business rules. Even business rules can be divided because some rules are very generic(like validation of an input field), while others are much more specific(calculation of interest). Not all business rules change at the same rate and for the same reasons.
Each use case should also be separated; they often do not change at the same time or for the same reason. For example, adding orders to the system will not change at the same rate as deleting orders.
We separate UI from business rules by using horizontal layers. And we do the same with business rules using vertical layers.
Chapter 17(Boundaries: Drawing Lines): The goal of architecture is to minimize the human resources that are needed to build and maintain the system. Boundaries are drawn to defer decisions for as long as possible and to keep decisions from polluting the core business logic.
The important boundaries to draw are between things that matters and thing that do not. The GUI does not matter to the business rules so there should be a line between them. The database also does not matter to the business rules so there should be a line there as well.
The critical fact here is that business logic can depend on an abstraction on the database but not on the database itself as shown on the image below.
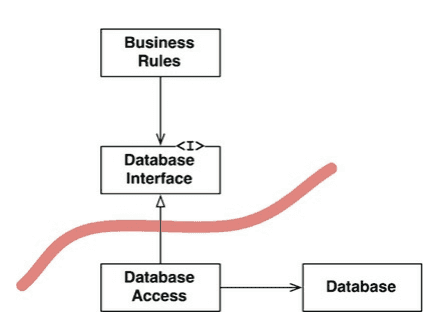
The business rules do not need to know if the database is implemented as a relational database, a NoSQL store or any other persistence mechanism. It is captured by letting the business rules depend on the abstraction instead.
The same boundary exists to the GUI since the same business rules could exist for both a fat client and a web client. The business rules cannot depend on a GUI implementation. The GUI is also just a detail.
Boundaries are an application of the Dependency Inversion Principle and the Stable Abstractions Principle. Dependency arrows point from lower-level details to abstractions.
Chapter 18 (Boundary Anatomy): A system is arranged into components and is defined by the boundaries that separate them.
The purpose of the boundaries is to contain changes, a change in one component should now require changes in another component. We build “firewalls” into the source code.
Even if the deployed system is a monolith, it can still have boundaries inside the system to aid with the development.
Boundary crossings can have different strategies, the most simple is a function call passing data. Up to calling a service across a network. The latter is a very strict boundary, but we still need to be strict about the boundaries not to pollute the architecture.
Chapter 19 (Policy And Level): All software systems implement policies describing how inputs are transformed into outputs. The distance from the input and outputs we can call the level.
In a good architecture, the direction of the dependencies should go from low to high. Policies that change together should be grouped (SRP and CCP).
Chapter 20 (Business Rules): It is funny how small this chapter is(5 pages) since it contains this quote
Business Rules are the reason a software system exists. It is the family jewels.
Some business rules are called “Critical business rules” they are the rules that are part of the business even if there was no software. The example is the interest on a loan; it does not matter if software calculates the interest, it will still make the bank money if a person did it.
The data the Critical Business Rules use is called “Critical Business Data”.
The Critical Business rules and data are encapsulated into Entities.
Not all business rules are easily modeled as entities but more like Use Cases. Those rules are related to an automated system and will not have a similar non-automated cousin.
There is a boundary between the use cases and the entities; entities should not know about the use cases. It is an example of the dependency inversion principle.
The important take away is to care a lot about the business rules, and they should be of unparallel quality.
Chapter 21 (Screaming Architecture): Many systems are built with a technical architecture in mind, like MVC, organized with models in one folder, views in another folder and controllers in a third folder. But this structure does not tell anything about what the system does.
Instead, we should focus on making an architecture the screams the purpose of the system.
Unfortunately the “how” is not explained at all. The focus is mostly on avoiding to lock the system into a framework. And making sure that the boundaries are placed, so it is possible to unit test all the use cases. Screaming architecture is explained much better in Domain Driven Design.
Chapter 22 (The Clean Architecture): There exist many different ideas on how to structure a software architecture. According to the author they are all very similar and differs mostly in their details, they all strive to create a separation of concerns.
The idea is captured in this overview “The clean architecture”
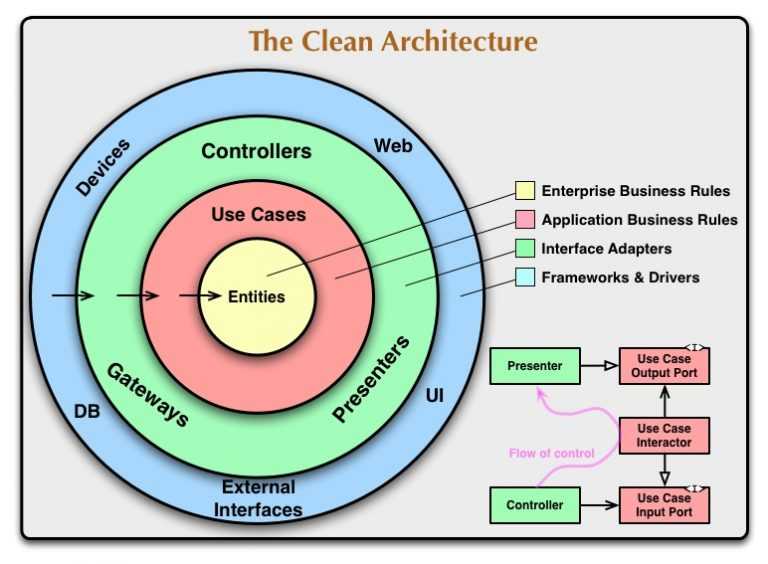
The further into the circle we go the more high level the software becomes. The inner circles are the business rules, the policies.
As a rule source code dependencies must always only point inwards. The innermost circle contains the critical business rules mentioned previously.
The use cases circle contains code to orchestrate the flow of data to and from the entities. We should expect that changes in this layer do not affect the entities. And also we should expect that changes to any external systems like databases should not affect the use cases.
Only changes in use cases should change the code in the use case layer.
The next layer contains interface adapters. They translate between the format most convenient for use cases to a format most suitable for the external consumers and vise versa.
The outer most layer contains all the framework parts, and we should strive to write only glue code in this layer.
Things to note:
- When passing data across a boundary, we should transform the data to fit the interface we are calling. If a database row is fetched in the outer most layer and is passed inwards, then it needs to be transformed because the layers inwards must not know about the database structure.
- Dependency Inversion Principle should be applied to reverse the dependency, as shown in the lower right corner of the diagram.
Chapter 23 (Presenters And Humble Objects): It can be difficult to test some behavior in a class. But often only part of the behaviors are difficult to test. Using the design pattern Humble objects, behaviors can be split into a piece that is easy to test, and a part where the difficult to test behavior is stripped to its bare essentials.
For example, GUIs are hard to test because a test cannot easily see the screen, but much of the logic is not difficult to test. So using the humble object pattern, the behavior can be split, so testing is possible.
Another example is database gateways. Here the SQL part is the humble object.
The patterns are often used as architectural boundaries to split the easy to test from the hard to test.
Chapter 24 (Partial Boundaries): Fully-fledged architectural boundaries are expensive. They require a lot of infrastructures to do data mapping, reciprocal polymorphic boundary interfaces, and dependency management to isolate the two sides. It involves a lot of work to build and maintain.
But it is possible to create a kind of placeholder that is not as expensive to build but still preserves the possibility to convert to a full boundary later.
The book mentions three ways to do it:
- Create all the work but keep everything in the same component. It removed the burden to make the two sides independently deployable.
- One-dimensional boundaries, using the strategy pattern a client can interface with a a service through a common interface. It does open up for back-channel communication between the client and the service implementation.
- A facade pattern can be added to shadow a collection of services. It even sacrifices dependency inversion.
To select between the options, we need to predict our future need which is of course error prone.
Chapter 25 (Layers and boundaries): It is easy to see the architecture in many a system as three parts, UI, business rules and persistence. But this is often not sufficient to create a flexible architecture.
The example from the chapter is a small game “Hunt the Wumpus”.
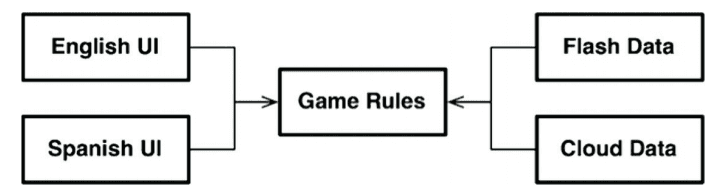
It is a good initial architecture. The game rules are independent of the rest of the concerns. All dependencies point towards the game rules. This allows us to add more persistence options and more language options without changing the game rules.
But in this architecture, we expect that the only axis of change in the UI is the language, but that is probably a naive approach. If we expand the architecture further by defining more boundaries, we get more options.
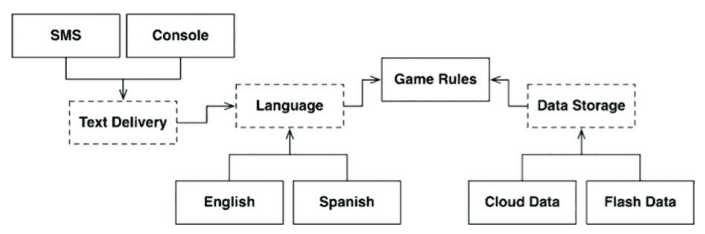
The new architecture allows us to have different delivery mechanisms for the UI while separating the language into another component, different from the delivery mechanism.
Boundaries exist everywhere and whether to add a boundary or ignore it is like trying to predict the future. It is a tradeoff between YAGNI(You Are not Going to Need It) and over-engineering.
Chapter 26 (The Main Component): In all systems, there is a component that starts the program and oversees everything. Even though the main component is where we often begin it is the most low level of all components.
Think of Main as the dirtiest of all the dirty componets
We should think of the Main component as a plugin component that handles configuration. It means that we can have different Main plugins for different environments, languages, and customers.
Chapter 27 (Services: Great And Small): Service-oriented architectures is a popular way to structure a system. Some of the reasons are
- Services seem strongly decoupled
- Services appear to support independent deployment and development
Without good architecture the reasons are moot.
Is service architecture an architecture? It depends, architecture is defined by how it separates high-level policy from low-level details.
If the service architecture just boils down to expensive function calls, then there is no architecture.
Oncle Bob explains two fallacies:
- The decoupling fallacy: Each service run in separate processes with a clearly defined interface. But if they are bound by shared data, they are not decoupled. If a new field is added to a shared record, all services that operate on that record type needs to be updated and agree on the interpretation of the field. The same goes for interfaces; a service interface is not more formal than function calls.
- The fallacy of independent development and deployment: The idea is that we can build a large system by composing multiple services where each service can be developed and deployed independently. It will also allow each service to be developed by different teams. The fallacy is somewhat coupled to the above. If the services are coupled through data or behavior, then they can not be developed independently, coordination between the teams are needed.
In the chapter is an example of this problem explained with a software system that does taxi aggregation. It shows both an example of a naive implementation and how to improve the situation.
By applying SOLID, we can get far. Each service will have an internal component architecture that must make it possible to develop and deploy the features independently.
Chapter 28 (The Test Boundary): Tests always depend on the code that is tested(of course). And there is never a dependence from the code to the test. From an architectural viewpoint, all tests are the same, they aid in the development and are often not deployed to production.
We must always strive to design for testability. The first problem to overcome is fragile tests. If tests are strongly coupled to the system, they must change whenever the system changes. Even trivial changes can cause many tests to break.
The first rule of software design: Don’t depend on volatile things
Make sure that components can be tested on the lowest possible level, so changes in low-level details do not break the test. The solution is to have a specific API that allows tests to bypass security and expensive resources. It will be a superset of the interface used by the UI.
An often used structure is to have a test class for each class in the system. It causes deep coupling between the system and the tests. The responsibility of the test API is to hide the structure of the system from the test so it can be tested even when the system is refactored.
I would like to have seen some examples on this point, but none is provided.
Chapter 29 (Clean embedded architecture): This chapter gives a different perspective on hardware / firmware / software. Software is built to have a long useful life. We know that hardware evolves continuously, and we do not want to change our software when the hardware gets updated. To help us interface with hardware, firmware implements a bridge with a common interface, no matter which hardware the software is running on.
Firmware is firmware because it depends on the hardware and because it can be hard to change when the hardware evolves. The problem is that it is not just embedded engineers that write firmware. If we bury SQL statements in our code or spread platform dependent code across our platform then by definition, we have created firmware! Because now our software are much harder to change.
Most of the rest of the chapter is mostly about embedded programming and how it is an area that could benefit a lot from clean architecture.
Chapter 30, 31, 32 (The Database, Web, Framework is a detail): Often we start by selecting a database for our new system. But we must remember that the database is a detail. It can be abstracted away and encapsulated completely; our business rules must not depend on it anyway. We should postpone the decision to use a database as long as possible because in some cases we end up without a need for it. In this case, we would have avoided all the complexity during the development.
The web is a UI, and as such, it is also just a detail. Referencing back to the game from chapter 25, we can abstract the UI away from the rest of our system. It provides us with the flexibility to implement multiple UIs without changing the rest of the system. We could reuse the same system for a web UI, an App, and a desktop application if we have implemented a clean architecture.
Frameworks are also just details. We should not marry a framework because the relationship is asymmetric. When selecting a framework we make a commitment to use it, but the framework author did not make any commitments. Often frameworks recommend us to integrate tightly. But this puts all the risk on our hands. If the project outgrows the framework it will be increasingly time-consuming to fight it and maybe the facilities are not up to par. So the advice is to keep any framework at arms length and only interface to it and consider it an implementation detail.
Chapter 33 (Case study: video sales): A complete example of a system incorporating all the advice from the rest of the book. The system implements a video sales and viewing platform. I did not find the example all that good, it is very short, and it does not show how the advice from the rest of the book is used all that good I think.
Chapter 34 (The missing chapter): The devil is in the details, even the best-planned effort will be destroyed instantly if we do not think about the implementation details. This is written by Simon Brown and offers some perspective on the advice in the rest of the book. I think it is one of the better chapters in the book. You should read it multiple times!
A few different ways to organize our code is discussed:
Package by layer: We can easily organize our code such that we have a package for the controllers, a package for the repositories and so on. But that does not scream what the architecture is implementing. When the software grows more packages are needed to allow us to develop and deploy independently.
Package by feature: Another way is to combine all layers and package by vertical slices instead. This is a better approach than package by layer since now each package should tell us something about the domain. But it is still suboptimal.
Package by component: A problem with most OOP languages is that we can not easily enforce architectural rules in them. For example, if we have a layered architecture with an OrdersController, OrdersService, and OrdersRepository. If we have a dependency from OrdersController to OrdersService and from OrdersService to OrdersRepository they all need to be public and nothing prevents a developer from adding a dependency directly from OrdersController to OrdersRepository.
A way to avoid this problem is to package by component. It rimes a lot with a micro-services architectural way of thinking. Each component is self-contained and exposes a clean interface to its consumers. In the example from before OrdersService and OrdersRepository are packaged as a component which allows us to make OrdersRepository private and enforce that only the OrdersService can access it.
If all types in an application are public then packages just become an organizational mechanism, with little value.
We can do better than having all types public. It is better to use the compiler to enforce architectural rules than self dicipline if possible.
Share

Legal Stuff