


Table Of Contents
Learn how to improve performance using scalability with the async and await keywords. When are asynchronous code able to help us and when will it make our performance worse.
We want good performance in our software, and we can get good performance in two ways. 1. Refactor the software to do its tasks faster. 2. We can improve the software scalability so we can handle more concurrent tasks.
Asynchronous code targets scalability making us use the resources of our servers better.
The inspiration for this article comes from the talk given by
Maarten Balliauw.
What is asynchronous code good for?
Most programs consist of single-threaded synchronous code. That causes the program to pause when it waits for disk or network. Only when the disk or network has responded the program continues processing.
It works great if we have a single task to complete. But, if we have a server that executes many tasks in parallel we need to consider scalability. It is where asynchronous code can help.
Asynchronous programming can in some cases help with performance by parallelizing a task. But, that is not its main benefit in day to day development.
Instead, the main benefit comes from making our code more scalable. The scalability feature of a system relates to how it handles a growing amount of work. And its potential to scale to accommodate that growth.
We can scale in two ways, horizontal and vertical
Horizontal scaling
If our system supports this scaling type, we can add more servers if we need to scale our service. The difficulty with scaling this way is that it has a few key constraints. Each server lives without knowing about the others. Because of that, we can only scale if the service is stateless.
When session data is part of the system, it makes scaling horizontally much harder. It increases the complexity of the solution, and we have a bottleneck with a shared cache or database.
A service build from RESTful principles is easy to scale horizontally.
We can use horizontal scaling no matter if we have synchronous or asynchronous code. There is no difference.
Vertical scaling
Another way of scaling is to improve how many requests our server can handle. Every single request will most likely not perform any better. But, we can increase the number of concurrent requests the server can handle.
When we scale vertically, we are not limited by the properties of RESTful because we are on a single server. Often vertical and horizontal scaling is used together. It makes REST a list of sound principles to follow.
How does async work?
We go through a few examples, and explain how both synchronous and asynchronous code work. From it arrives at the server to it sends its reply back.
Synchronous requests
Inside our C# application, no matter if it is a .NET Core or .NET application, is a thread pool. When a request hits the service, a thread is drawn from the thread pool.
This thread handles all processing needed until the response is sent. If we need to make a slow database query as part of the request, the thread pauses. Nothing happens before the database query is complete.
Let us assume this scenario; we need to make a database query that takes a long time to complete. As long as we have available threads, we can allocate a new thread for every incoming request. But as soon as we hit the max amount of threads, we rejects incoming requests.
Most of the threads are waiting for the database query to complete. And we end up with a server that is not doing much, except waiting but is rejecting requests. Not a good situation, and a bad underutilization of resources.
Asynchronous requests
With asynchronous code, we can improve the situation quite a bit.
A request starts in the same way by fetching a thread from the thread pool. But now we have marked our database query method as async. It instructs the .NET runtime that we expect the method call to take a while to complete. Now the thread is freed and put back in the thread pool.
When the database query completes, a thread is allocated from the thread pool. This thread allows us to continue the request.
Now we only have threads allocated that have work to do. When we need to wait for IO, we allow the threads to continue with other tasks. We are not guaranteed to get the same thread back. But that is not a problem since the .NET runtime handles the details.
Using asynchronous code does not give an increased performance on a development machine. The reason is that there is not enough load to see the overall benefit. But for a production environment, it can process more requests.
Is asynchronous code worth it?
Later we go through how easy it is to implement. But first, let us look at some numbers and see if it can make sense to use asynchronous code in the first place.
I took this example from this article. Let us assume we have a 16 core server and a thread pool with 1 thread per core, 16 threads. If we create 1000 requests to the service, the 16 threads are able to handle all 1000 requests.
Let us assume that some lousy programmer put a Sleep(200) as the first code on each request. We would assume that each request would be 200 ms slower, but actually, it is much worse!
The first 16 threads block for 200 ms while processing the request. When they complete their requests the next 16 requests are handled and blocks for another 200 ms. Now the average response time goes up to 6 seconds for 1000 requests.
But the resource allocation on the server is low, not indicating any problem. A small amount of blocking code can cause huge problems with throughput.
Since a thread needs an actual CPU to run we can not increase the number of threads to thousands or millions. It causes too much congestion on the CPU to be useful.
Generally, you want less than 1000 of them(threads), and preferably < 100
Diagnosing .NET Core ThreadPool Starvation
Asynchronous code is not just worth it; it is essential for high performing services!
Asynchronous coding
Now to the exciting part, how do we implement asynchronous code in our service?
C# comes with two keywords built in “async” and “await.” They go hand in hand to allow us to easily implement asynchronous code.
When we mark a method with async, it gives two things. We can use await inside it and it transforms the method into a compiler generated state machine.
Notice the async keyword does not make anything async. That is the purpose of the await keyword. Await tells the compiler that the async method cannot continue. Before the awaited process has finished.
We can only await async methods. If an async method does not have any await inside it is run as a normal synchronized method.
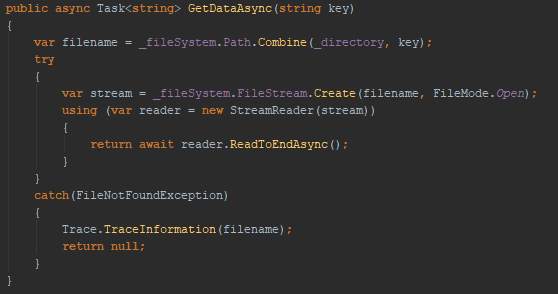
In this example, the call to the filesystem goes through the method “GetDataAsync”. The async and await keyword allows the thread to return to the thread pool. When the call returns, a new thread is allocated to continue processing.
In the code example, the return type is a Task<string> instead of string. Async methods can return either Task or Task<T>. A Task represents the execution of the method and is a state machine.
The state machine can be in a few different states. IsCanceled, IsCompleted, and IsFaulty which are accessed through the field Status.
It is the state machine that allows the .NET runtime to make it easy for us to implement asynchronous code. For more details, I recommend looking at C# In a Nutshell, chapter 14.
We can use the async return types Task and Task, without the async keyword but then it runs sync. It is bad practice because it reveals the implementation details from our method.
Asynchronous in the bigger perspective
The example above shows how to apply async to a single method, but that does not show us how to use it in a larger system.
We must apply async through the layers. Most applications pass a request through different layers to build the response. We need to have async where the IO happens, so we should start bottom up.
Let us set up an example. We have an ASP.NET controller with an action to get a user based on its user id. The controller passes the request down through a service layer. In turn, it requests the user from a repository that fetches it from a file on disk.
It is the last part, fetching from disk, that causes IO that we want to have async. Let us see some code.
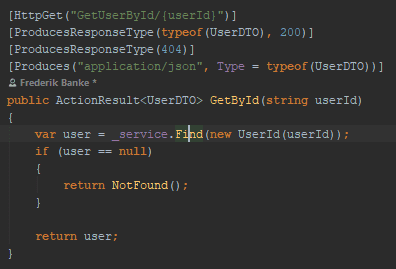
Controller code
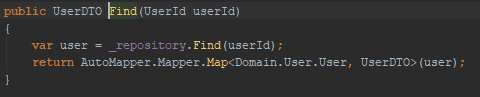
Service layer
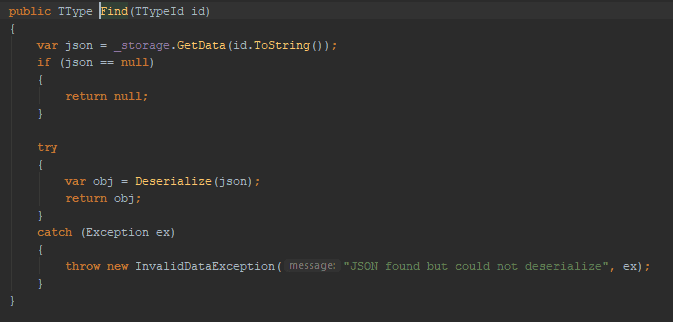
Repository code
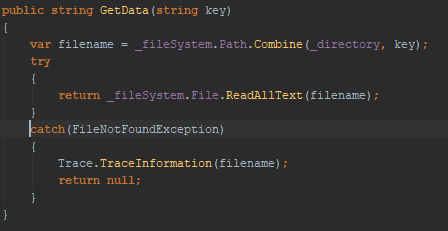
Accessing disk
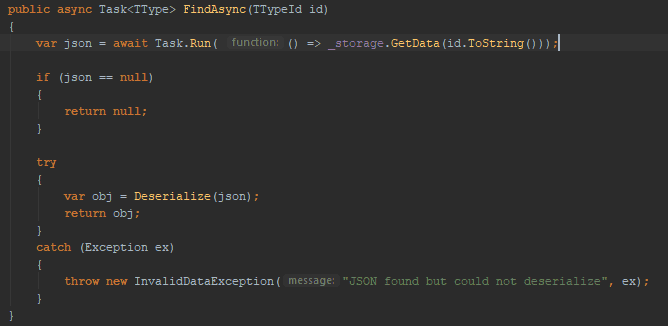
The IO is in the GetData method. It is where we want to add async code. We create the GetDataAsync method. Add the async keyword and changes the return type to Task<string>. We also need to change it to read the file using a StreamReader so we can await it.
Accessing disk using async
In the repository code, we also need to make changes to consume the new async method.
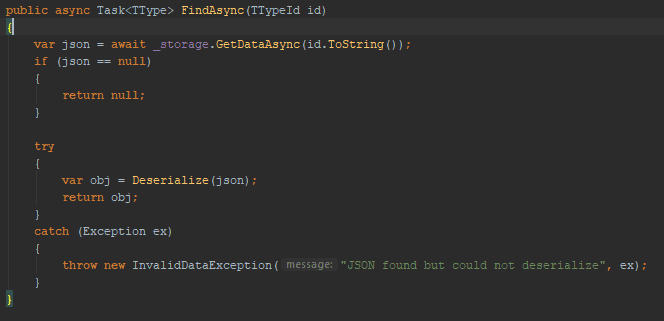
Updated Find method to use async
In the repository, we can get away with making the method async. Also, add the await keyword on the GetDataAsync method call.
We continue up the chain to the service layer and add the async code.

Async service layer.
Finally, we add async to the controller.
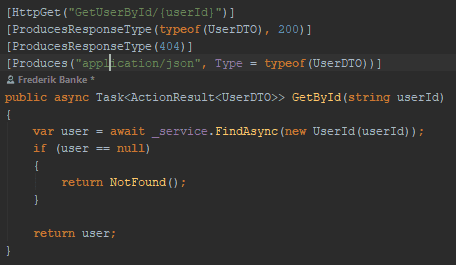
Async controller
Now we have added async to the whole stack down to the actual IO. It allows the .NET runtime to release the thread to the thread pool while we wait for the disk to fetch data.
We should not mix synchronous and asynchronous code without careful considerations. We should strive for async all the way.
We could use “.Result” or “.Wait” on the task object to switch from synchronous to asynchronous code. It is a bad idea since it causes the thread to block until the asynchronous code returns. It is defeating the whole purpose of adding async in the first place.
Which work should we use async for?
Async is not the solution to all thread blocking code. Threads block if we call a method that performs some heavy computation or if it needs to wait for IO. It is only in the case of IO that we get any gain from using async.
IO bound
Any task that accesses the file system or any external service is good candidates for async.
Computational bound
Any algorithm that takes a long time and is CPU or memory intensive are bad candidates for async.
Examples
Adding an entity using entityframework: IO happens when we call save. Not when we initially add the entity. It is not a good candidate for using async. Entityframework supplies us with an async add method, but we gain nothing from using it.
Entityframeworks SaveChangesAsync is a good candidate for async. It does IO to the database.
Integrating async with legacy code
What if we need to integrate our code with code that is not async aware and we can not change it? The old code is directly awaitable. But we can cheat and make it awaitable by creating a task. Some extra discussion from stack overflow.
As discussed before, it is not optimal to create a task in synchronous code. It causes the main thread to block until the task returns. But the code is still correct, just not as scalable. It can be done as shown in this example:
Going from asynchronous to synchronous code
Closing remarks
I hope this overview into asynchronous code gives you some ideas to go try it in your own code.
Happy coding!
Share

Legal Stuff